Crowdseed
Accelerating Bible translation, sentence-by-sentence.The Challenge
A typical Bible translation today takes 15 years. But what if we could build a tool that spreads the work of translation to the local community, and complete the translation in two years?
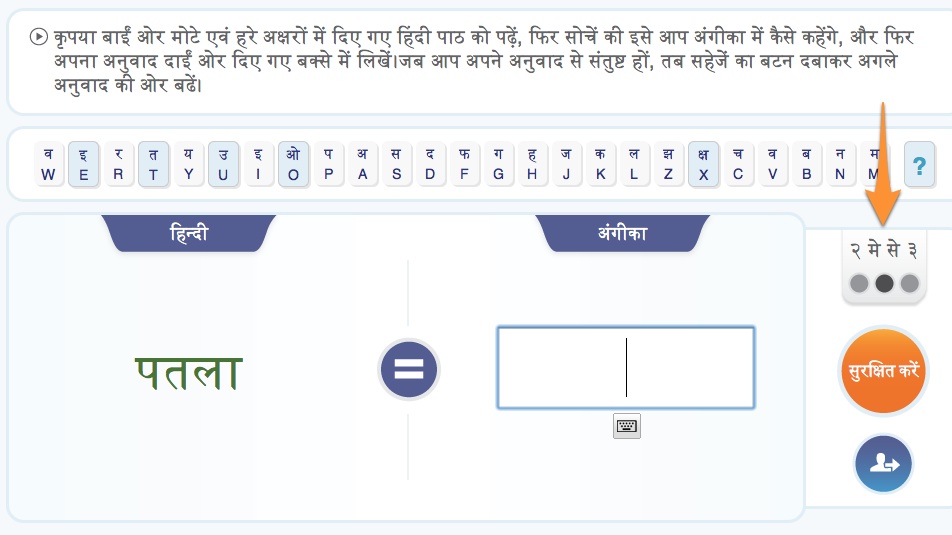
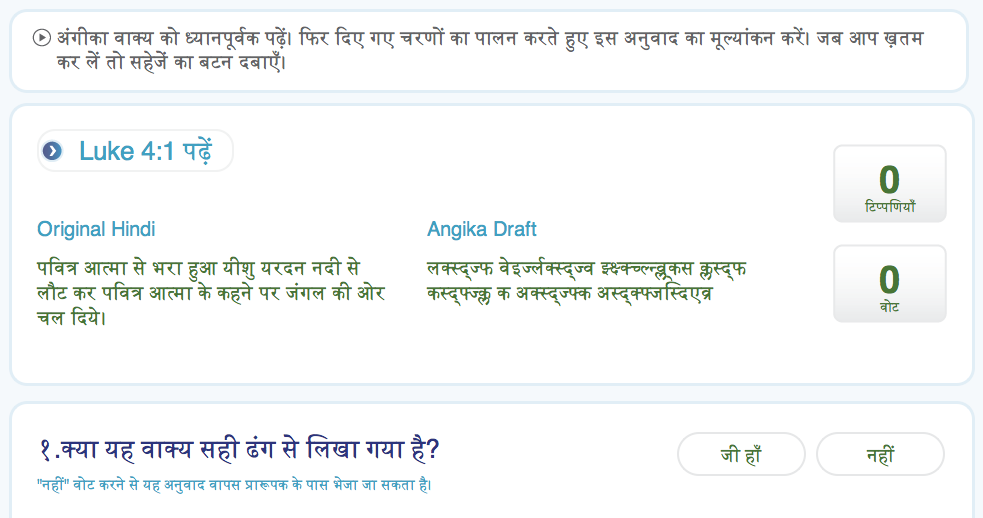
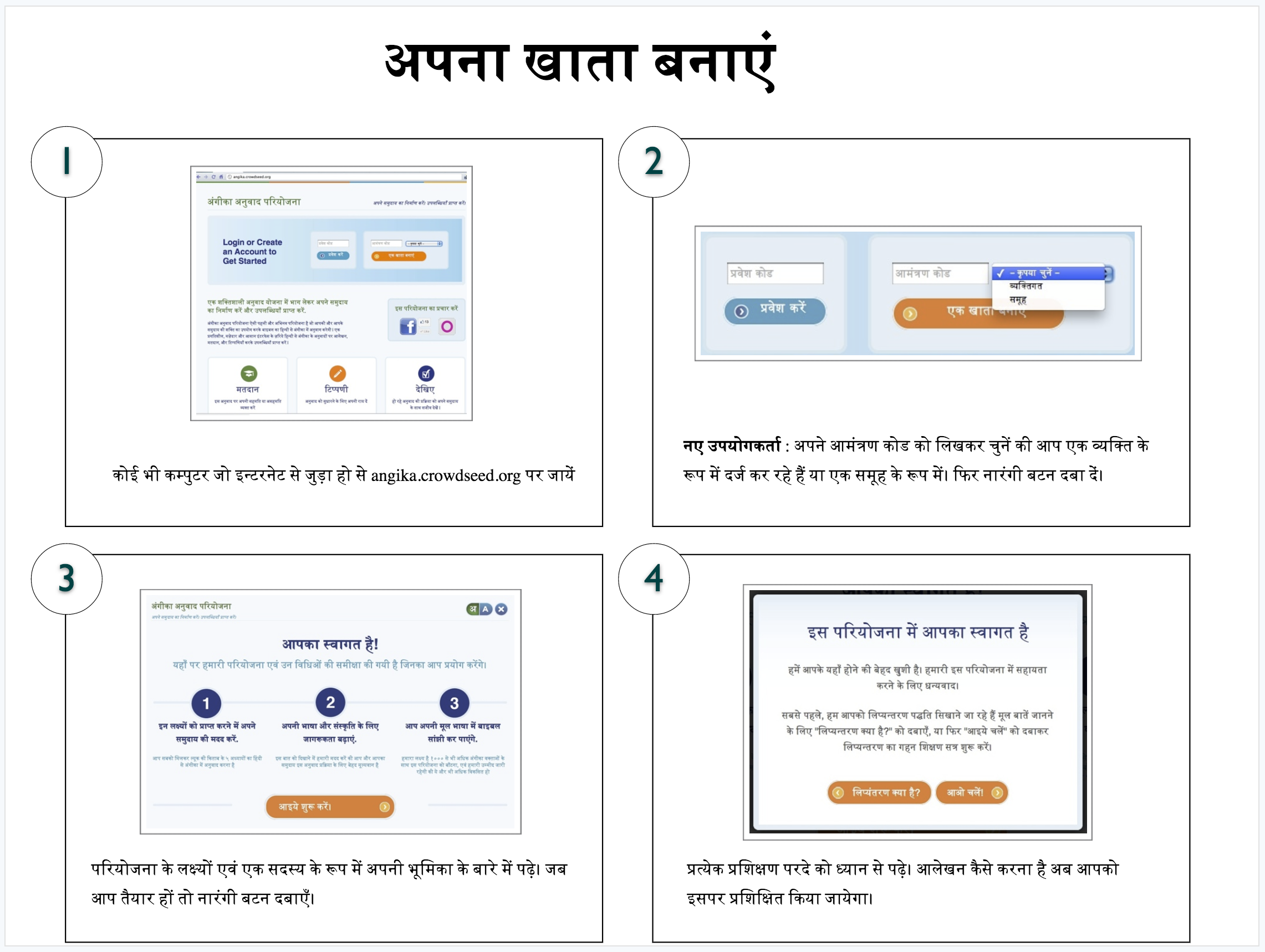
Working with The Seed Company, I helped design and fully built a web application that would enable a community of native speakers to crowdsource a Bible translation from Hindi to Angika, a sub-dialect specific to the Bihar region of India.
Learnings
- As part of the requirements, I converted the New Testament book of Luke from a Paratext™ Hindi source text to a format that could be stored in a relational database, sentence-by-sentence and organized by pericope. This was much simpler than attempting to do so from an English source text, since the Devanagari character set uses either a simple "danda" character or an English question mark for sentence termination—both of which are not used in any other context. Compare this to English natural language processing, where a period can be a sentence terminator, an abbreviation terminator, or even exist in ellipsis!
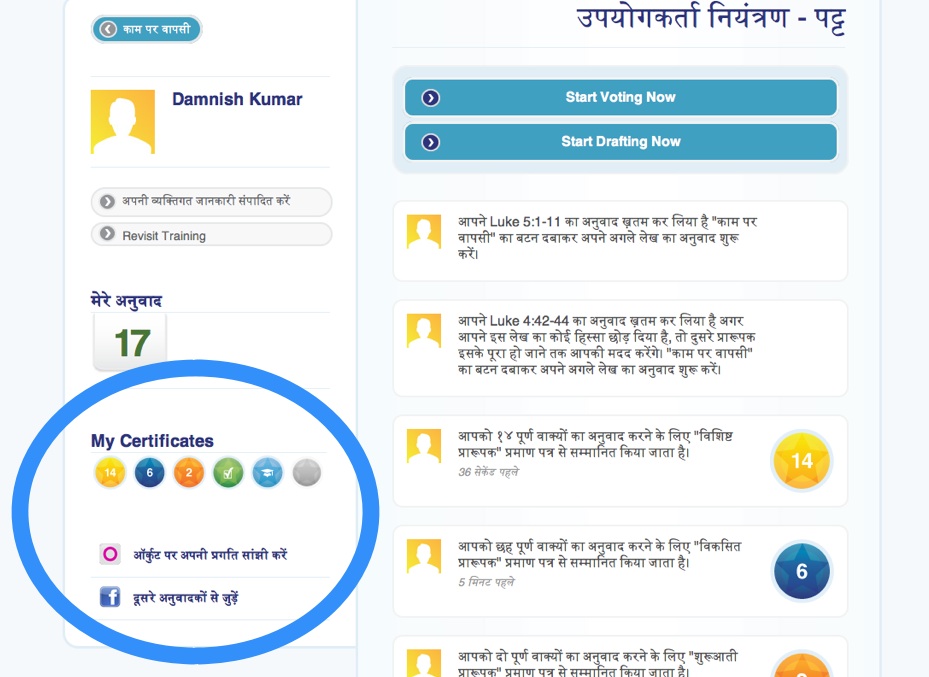
- We learned that after designing the system to be used by individuals, actual human translators worked together in groups, not by themselves. The community aspect was very important for this project and required a pivot halfway through to accommodate the group aspect.
- In order to gauge participation and user experience, I was able to review footage acquired by Silverback and tweak several key aspects of the interface in order to accommodate some issues with original assumptions.
- I also built out an administrator analytics panel that presented useful information about usage of the system and total numbers of translations and votes.
Source code is not currently available.
Technologies
- HTML5
- CSS3
- PHP 5
- JavaScript (ES5)
- jQuery 1.11
- Zend Framework 1
- Twitter Bootstrap 2.3.2
- Git
- Subversion
-
There were a number of interactions that happened via AJAX calls. All of them utilizes jQuery's AJAX functionality.
-
We created two versions of the site: one in English, and one in Hindi, although Hindi was the primary interface language. This required UTF-8 encodings across the board, plus integration with PO/MO files for the actual string translations.
Note that it's challenging to find mispellings when using a non-Latin character set!
Duration
About 11 months
(2011)